SPI协议简述
标准SPI
SPI(Serial Peripheral
Interface)是一种高速、全双工的同步串行通信协议,广泛应用于微控制器与外设(如Flash、传感器、显示屏)之间的通信。
标准SPI时序如下(CPOL = 1,CPHA = 0):
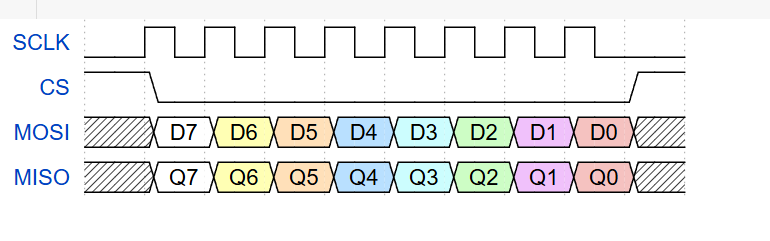 标准SPI时序图
标准SPI时序图
注:图中没有标出如下的建立/保持时间,这些详细时序要求可以参考芯片手册。
- tCSS:
CS建立时间(CS下降沿到第一个时钟上升沿)
- tCSH:
CS保持时间(最后时钟下降沿到CS上升沿)
- tSU:
数据建立时间(数据稳定到时钟采样沿)
- tH:
数据保持时间(时钟采样沿后数据保持稳定)
SPI有4种工作模式,由两个参数决定:
- CPOL(时钟极性):空闲时时钟线的电平(0=低电平,1=高电平)
- CPHA(时钟相位):数据采样时刻(0=第一个边沿,1=第二个边沿)
| 模式 |
CPOL |
CPHA |
空闲时钟 |
采样边沿 |
输出边沿 |
| 0 |
0 |
0 |
低电平 |
上升沿 |
下降沿 |
| 1 |
0 |
1 |
低电平 |
下降沿 |
上升沿 |
| 2 |
1 |
0 |
高电平 |
下降沿 |
上升沿 |
| 3 |
1 |
1 |
高电平 |
上升沿 |
下降沿 |
模式0和模式3最常用,大多数SPI设备支持其中之一。主从设备必须使用相同的模式才能正常通信。
详细时序如下(时钟建立时间不准)
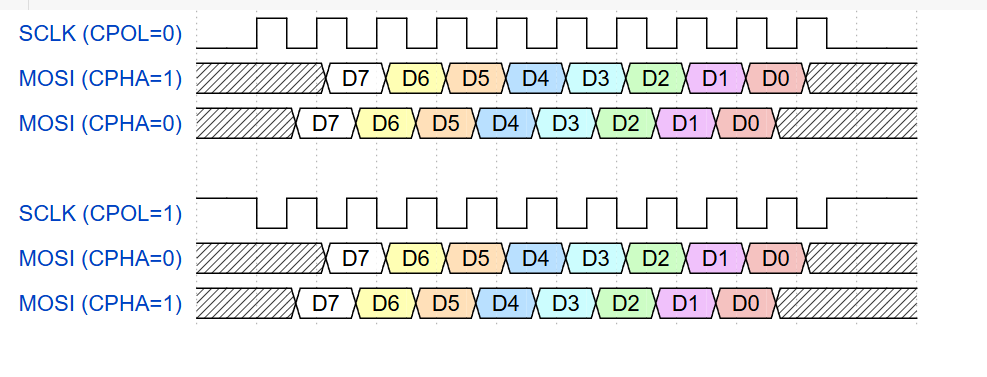 SPI工作模式
SPI工作模式
标准SPI虽然简单可靠,但在现代应用中面临明显的带宽瓶颈。由于采用单线传输方式,MOSI和MISO各占一根线进行半双工数据传输,即使时钟频率达到50MHz,单线传输速率也仅有6.25MB/s。这在大容量Flash应用中尤为突出:从128MB
Flash读取1MB数据需要约160ms,系统启动时加载数MB固件会产生明显延迟,而实时应用(如视频、图像处理)更是无法满足带宽需求。
增强型SPI
一个最简单的办法是增加数据线线,让传输并行化,因此诞生了Dual
SPI(双线)、Quad SPI(四线)以及Octal
SPI(8线)。标准SPI采用全双工设计,MOSI和MISO是独立的单向线路,可同时收发数据。而DSPI/QSPI/OSPI采用半双工设计,数据线是双向复用的,同一时刻只能进行读或写操作。这种设计牺牲了全双工能力,但通过增加并行数据线大幅提升了单向传输带宽。
三种增强型SPI协议传输可以分成三个阶段:命令、地址、数据,以QSPI为例,其传输时序为:
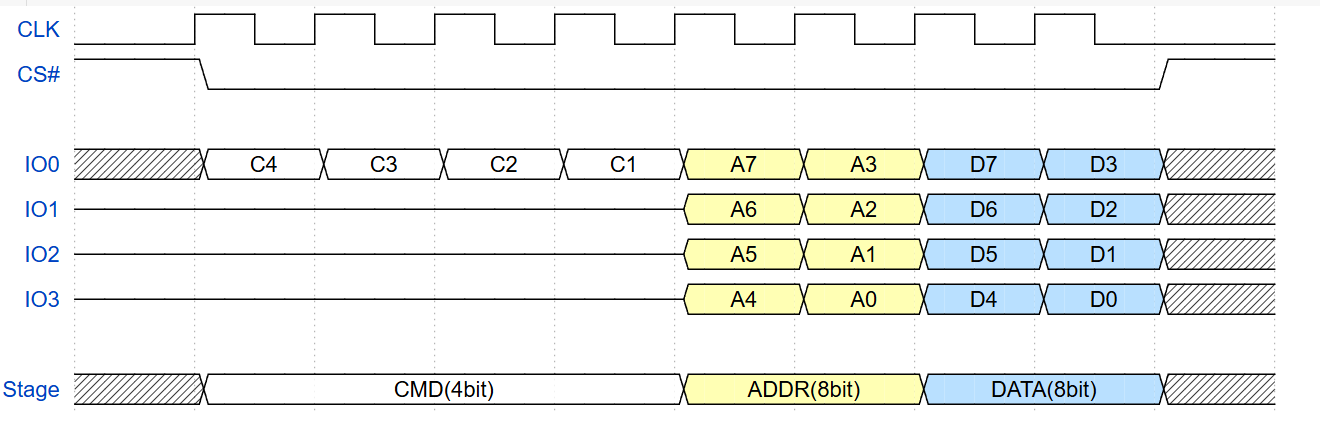 QSPI发送模式
QSPI发送模式
图中,命令为4bit,单线传输;地址和数据都是8bit,4线传输。实际上,命令线和地址线都可以用1/2/4/8线传输(也就是向下兼容),或者省略,进行数据阶段的传输。
硬件平台
从K230芯片架构可以看出,K230有一个Octal SPI控制器(OPI)和两个Quad
SPI控制器(QPI)。
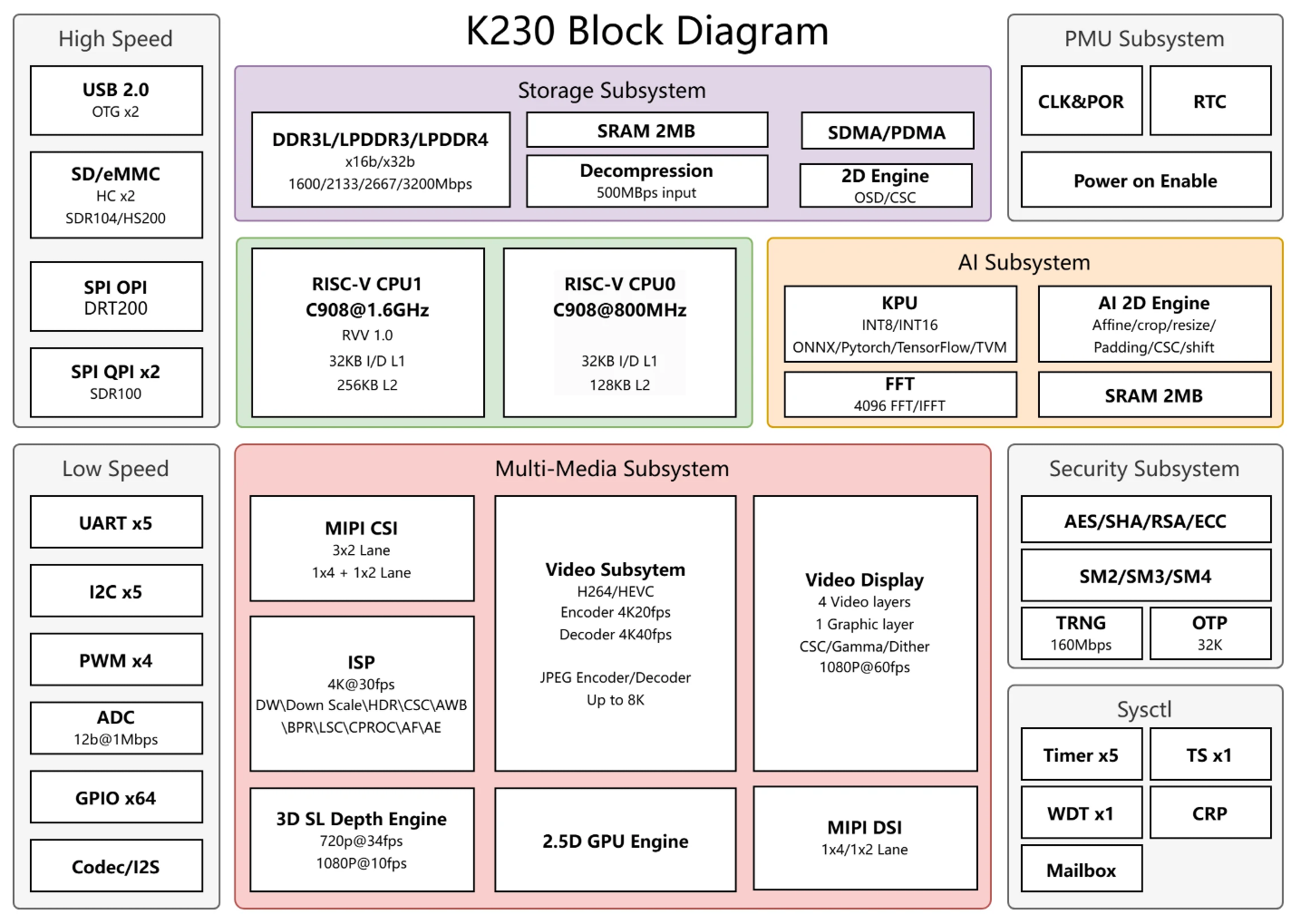 K230芯片架构
K230芯片架构
对于OPI,其支持1/2/4/8线传输模式,最大时钟频率为200MHz。而QPI控制器支持1/2/4线传输模式,最大频率为100MHz。
需要注意的是,K230
的SPI控制器内部集成了一套自己的DMA(手册里叫Internal DMA),用来直接在
SPI
与内存之间搬运数据。它和系统外设DMA控制器PDMA是两套独立的硬件,互不复用通道,所以SPI的DMA传输不需要走统一的PDMA框架,对PDMA驱动也没有依赖。
驱动架构设计
配置部分
对于RT-smart而言,其内核中有两个和SPI相关的组件:SPI和QSPI,SPI的基础配置结构体rt_spi_configuration定义了标准SPI的核心参数,而QSPI配置结构体rt_qspi_configuration在标准SPI基础上扩展了多线传输能力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
struct rt_spi_configuration
{
rt_uint8_t mode;
rt_uint8_t data_width;
#ifdef RT_USING_DM
rt_uint8_t data_width_tx;
rt_uint8_t data_width_rx;
#else
rt_uint16_t reserved;
#endif
rt_uint32_t max_hz;
};
struct rt_qspi_configuration
{
struct rt_spi_configuration parent;
rt_uint32_t medium_size;
rt_uint8_t ddr_mode;
rt_uint8_t qspi_dl_width ;
};
|
这种继承设计使得QSPI配置向下兼容标准SPI,同时qspi_dl_width支持8线参数,因此K230的所有SPI控制器(包括OPI和QPI)都可以注册为QSPI总线。
在RT-smart中,QSPI和SPI设备共用同一套操作接口rt_spi_ops:
1
2
3
4
5
6
7
8
|
struct rt_spi_ops
{
rt_err_t (*configure)(struct rt_spi_device *device, struct rt_spi_configuration *configuration);
rt_ssize_t (*xfer)(struct rt_spi_device *device, struct rt_spi_message *message);
};
|
驱动开发的核心工作就是实现这两个函数指针:
configure:根据配置参数初始化硬件寄存器xfer:执行实际的数据传输操作
由于QSPI和标准SPI兼容同一套接口,rt_spi_ops内部两个虚函数参数用的是rt_spi_device,rt_spi_configuration和rt_spi_message。因此,驱动层需要利用rt_qspi_device->parent和rt_spi_device首地址相同的特性进行强制转换:
1
2
3
4
5
6
7
8
9
10
11
12
| rt_err_t drv_spi_configure(struct rt_spi_device *device, struct rt_spi_configuration *configuration)
{
struct rt_qspi_device *qspi_device = (struct rt_qspi_device *)device;
struct rt_qspi_configuration *qspi_cfg = &qspi_device->config;
}
rt_ssize_t drv_spi_xfer(struct rt_spi_device *device, struct rt_spi_message *message)
{
struct rt_qspi_device *qspi_device = (struct rt_qspi_device *)device;
struct rt_qspi_message *qspi_msg = (struct rt_qspi_message *)message;
}
|
下面看看应用层调用QSPI总线的流程,需要做哪些配置,使用了哪些函数,以及用户的参数是如何从应用层传递到驱动层的ops吧。详细代码参考:K230
SPI utest
抛开GPIO的功能配置以及输入输出模式选择,首先需要找到已注册的SPI总线,然后将设备挂载到总线上。
1
2
3
4
5
|
struct rt_spi_bus *spi_bus = (struct rt_spi_bus *)rt_device_find(SPI0_BUS_NAME);
qspi_dev = (struct rt_qspi_device *)rt_malloc(sizeof(struct rt_qspi_device));
ret = rt_spi_bus_attach_device(&(qspi_dev->parent), SPI0_DEV_NAME0, SPI0_BUS_NAME, RT_NULL);
|
由于RT-smart不支持直接访问SPI总线,因此应用层必须绑定设备,以设备的形式进行总线操作。这种设计允许一条总线上挂载多个设备,每个设备可以有独立的配置参数。
接下来是创建配置结构体并设置参数,然后调用配置函数:
1
2
3
4
5
6
7
8
9
10
11
|
struct rt_qspi_configuration qspi_cfg;
qspi_cfg.parent.mode = RT_SPI_MODE_0 | RT_SPI_MSB;
qspi_cfg.parent.data_width = 8;
qspi_cfg.parent.max_hz = 1000000;
qspi_cfg.parent.reserved = 0;
qspi_cfg.qspi_dl_width = 1;
qspi_cfg.medium_size = 0;
qspi_cfg.ddr_mode = 0;
ret = rt_qspi_configure(qspi_dev, &qspi_cfg);
|
核心是rt_qspi_configure这个函数,它的实现在dev_qspi_core.c中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| rt_err_t rt_qspi_configure(struct rt_qspi_device *device, struct rt_qspi_configuration *cfg)
{
RT_ASSERT(device != RT_NULL);
RT_ASSERT(cfg != RT_NULL);
...............................
if (device->config.medium_size == cfg->medium_size &&
device->config.ddr_mode == cfg->ddr_mode &&
device->config.qspi_dl_width == cfg->qspi_dl_width &&
device->config.parent.data_width == cfg->parent.data_width &&
device->config.parent.mode == (cfg->parent.mode & RT_SPI_MODE_MASK) &&
device->config.parent.max_hz == cfg->parent.max_hz)
{
return RT_EOK;
}
device->config.parent.mode = cfg->parent.mode;
device->config.parent.max_hz = cfg->parent.max_hz;
device->config.parent.data_width = cfg->parent.data_width;
#ifdef RT_USING_DM
device->config.parent.data_width_tx = cfg->parent.data_width_tx;
device->config.parent.data_width_rx = cfg->parent.data_width_rx;
#else
device->config.parent.reserved = cfg->parent.reserved;
#endif
device->config.medium_size = cfg->medium_size;
device->config.ddr_mode = cfg->ddr_mode;
device->config.qspi_dl_width = cfg->qspi_dl_width;
return rt_spi_bus_configure(&device->parent);
}
|
上面的代码我省略了软件CS这一部分,rt_qspi_configure中,对比了rt_qspi_device->config和rt_qspi_configuration的新旧版配置,避免重复配置硬件,将用户配置保存到device->config中,调用底层总线配置函数
rt_qspi_device的定义展示了设备、配置和总线的关系:
1
2
3
4
5
6
7
8
9
10
|
struct rt_qspi_device
{
struct rt_spi_device parent;
struct rt_qspi_configuration config;
void (*enter_qspi_mode)(struct rt_qspi_device *device);
void (*exit_qspi_mode)(struct rt_qspi_device *device);
};
|
rt_qspi_device的父类是rt_spi_device,而它自己也有一个qspi配置结构体rt_qspi_configuration,再看rt_spi_bus_configure这个函数,它的实现在:dev_spi_core.c,这是配置流程的最后一环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| rt_err_t rt_spi_bus_configure(struct rt_spi_device *device)
{
rt_err_t result = -RT_ERROR;
if (device->bus != RT_NULL){
result = spi_lock(device->bus);
if (result == RT_EOK){
if (device->bus->owner == device){
result = device->bus->ops->configure(device, &device->config);
if (result != RT_EOK){
LOG_E("SPI device %s configuration failed", device->parent.parent.name);
}
}else{
result = -RT_EBUSY;
}
spi_unlock(device->bus);
}
}else{
result = RT_EOK;
}
return result;
}
|
当确认获取锁后,rt_spi_bus_configure会把配置部分传递给ops结构体:device->bus->ops->configure(device, &device->config)。
这里存在一个需要注意的问题:rt_spi_bus_configure接收的device参数类型是rt_spi_device(即rt_qspi_device->parent),因此传递给驱动层的配置参数&device->config实际指向rt_qspi_device->parent.config,而不是rt_qspi_device->config.parent。
这意味着驱动层的 configure 函数收到的第二个参数
configuration 其实并不是应用层程序在
rt_qspi_configure
里设置的那份配置。因此驱动实现时没法使用这个参数,而是要先把
device 强转回 rt_qspi_device,再从
qspi_device->config(里取真正的配置:
1
2
3
4
5
6
7
| rt_err_t drv_spi_configure(struct rt_spi_device *device, struct rt_spi_configuration *configuration)
{
struct rt_qspi_device *qspi_device = (struct rt_qspi_device *)device;
struct rt_qspi_configuration *qspi_cfg = &qspi_device->config;
}
|
传输部分
QSPI消息结构体rt_qspi_message完整描述了传输信息的所有参数。其定义位于:dev_spi.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| struct rt_qspi_message
{
struct rt_spi_message parent;
struct
{
rt_uint8_t content;
rt_uint8_t qspi_lines;
} instruction;
struct
{
rt_uint32_t content;
rt_uint8_t size;
rt_uint8_t qspi_lines;
} address, alternate_bytes;
rt_uint32_t dummy_cycles;
rt_uint8_t qspi_data_lines;
};
|
这个结构体继承自标准SPI消息rt_spi_message:
1
2
3
4
5
6
7
8
9
10
| struct rt_spi_message
{
const void *send_buf;
void *recv_buf;
rt_size_t length;
struct rt_spi_message *next;
unsigned cs_take : 1;
unsigned cs_release : 1;
};
|
rt_qspi_message对应增强型SPI的三个传输阶段:
- instruction:命令阶段,包含命令内容和线数配置
- address:地址阶段,包含地址内容、长度和线数配置
- parent:数据阶段,继承自
rt_spi_message,包含发送/接收缓冲区和长度
每个阶段都可以独立配置线数(1/2/4/8),实现灵活的传输组合。例如下面的配置实际是把QSPI当标准SPI使用:命令和地址阶段都省略(size=0),只进行数据阶段的单线传输。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
struct rt_qspi_message msg;
rt_memset(&msg, 0, sizeof(msg));
msg.instruction.content = 0;
msg.instruction.qspi_lines = 1;
msg.address.content = 0;
msg.address.size = 0;
msg.address.qspi_lines = 1;
msg.qspi_data_lines = 1;
msg.dummy_cycles = 0;
msg.parent.send_buf = tx_data;
msg.parent.recv_buf = rx_data;
msg.parent.length = TEST_DATA_LENGTH;
msg.parent.cs_take = 1;
msg.parent.cs_release = 1;
msg.parent.next = RT_NULL;
ret = rt_qspi_transfer_message(qspi_dev, &msg);
|
rt_qspi_transfer_message函数是传输流程的入口,其实现展示了内核如何处理总线共享和设备切换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| rt_ssize_t rt_qspi_transfer_message(struct rt_qspi_device *device, struct rt_qspi_message *message)
{
rt_ssize_t result;
RT_ASSERT(device != RT_NULL);
RT_ASSERT(message != RT_NULL);
result = rt_mutex_take(&(device->parent.bus->lock), RT_WAITING_FOREVER);
if (result != RT_EOK){
rt_set_errno(-RT_EBUSY);
return 0;
}
rt_set_errno(RT_EOK);
if (device->parent.bus->owner != &device->parent){
result = device->parent.bus->ops->configure(&device->parent, &device->parent.config);
if (result == RT_EOK){
device->parent.bus->owner = &device->parent;
}else{
rt_set_errno(-RT_EIO);
goto __exit;
}
}
result = device->parent.bus->ops->xfer(&device->parent, &message->parent);
if (result == 0){
rt_set_errno(-RT_EIO);
}
__exit:
rt_mutex_release(&(device->parent.bus->lock));
return result;
}
|
SPI总线经常遇到多设备共享的情况。除了互斥锁,RT-smart还通过总线所有权机制来处理:对比当前总线拥有者是否是当前设备,如果不是则重新配置device->parent.bus->ops->configure(&device->parent, &device->parent.config)。这样不同配置的设备可以共享同一条总线。配置完成后,调用驱动层ops传输数据:device->parent.bus->ops->xfer(&device->parent, &message->parent)
实现细节
之前提到,驱动层除了中断注册,设备注册等,其核心就是实现rt_spi_ops这个结构体中的虚函数,也就是总线的操作方法:
1
2
3
4
5
| static const struct rt_spi_ops k230_qspi_ops =
{
.configure = k230_spi_configure,
.xfer = k230_spi_xfer,
};
|
在驱动中,我们需要实现初始化rt_hw_qspi_bus_init,配置k230_spi_configure,传输k230_spi_xfer以及中断回调函数k230_spi_irq,驱动的详细代码参考:K230
SPI驱动
初始化
驱动的初始化发生在内核启动的过程中,在用户态启用之前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| int rt_hw_qspi_bus_init(void)
{
rt_err_t ret;
int i;
for (i = 0; i < sizeof(k230_spi_devs) / sizeof(k230_spi_devs[0]); i++)
{
k230_spi_devs[i].base = rt_ioremap((void *)k230_spi_devs[i].pa_base, k230_spi_devs[i].size);
ret = rt_qspi_bus_register(&k230_spi_devs[i].dev, k230_spi_devs[i].name, &k230_qspi_ops);
if (ret)
{
LOG_E("%s register fail", k230_spi_devs[i].name);
return ret;
}
rt_event_init(&k230_spi_devs[i].event, k230_spi_devs[i].event_name, RT_IPC_FLAG_PRIO);
rt_hw_interrupt_install(k230_spi_devs[i].vector + SSI_TXE, k230_spi_irq, &k230_spi_devs[i], k230_spi_devs[i].name);
rt_hw_interrupt_umask(k230_spi_devs[i].vector + SSI_TXE);
rt_hw_interrupt_install(k230_spi_devs[i].vector + SSI_RXF, k230_spi_irq, &k230_spi_devs[i], k230_spi_devs[i].name);
rt_hw_interrupt_umask(k230_spi_devs[i].vector + SSI_RXF);
rt_hw_interrupt_install(k230_spi_devs[i].vector + SSI_DONE, k230_spi_irq, &k230_spi_devs[i], k230_spi_devs[i].name);
rt_hw_interrupt_umask(k230_spi_devs[i].vector + SSI_DONE);
rt_hw_interrupt_install(k230_spi_devs[i].vector + SSI_AXIE, k230_spi_irq, &k230_spi_devs[i], k230_spi_devs[i].name);
rt_hw_interrupt_umask(k230_spi_devs[i].vector + SSI_AXIE);
}
return RT_EOK;
}
INIT_DEVICE_EXPORT(rt_hw_qspi_bus_init);
|
驱动初始化在内核启动时完成,通过INIT_DEVICE_EXPORT,实现主要工作包括:
寄存器映射:通过rt_ioremap将物理地址映射到虚拟地址空间,k230_spi_devs[i].base被内存映射IO指向SPI相关的寄存器,也就是从k230_spi_devs[i].pa_base开始,向高位偏移k230_spi_devs[i].size字节,具体Memory
Map参数参考board.h。
总线注册:调用rt_qspi_bus_register注册QSPI总线。
中断注册:注册发送空(SSI_TXE)、接收满(SSI_RXF)、传输完成(SSI_DONE)和AXI错误(SSI_AXIE)四个中断。
配置
配置函数k230_spi_configure首先进行参数校验,确保线数不超过硬件限制(OPI最大8线,QPI最大4线),数据宽度在4-32位范围内,时钟频率不超过硬件最大值。
然后是配置时钟,先获取SPI控制器的时钟频率,然后计算分频系数:
1
2
3
4
5
6
7
| if (qspi_bus->idx == 0){
qspi_clk = sysctl_clk_get_leaf_freq(SYSCTL_CLK_SSI0);
}else if (qspi_bus->idx == 1){
qspi_clk = sysctl_clk_get_leaf_freq(SYSCTL_CLK_SSI1);
}else if (qspi_bus->idx == 2){
qspi_clk = sysctl_clk_get_leaf_freq(SYSCTL_CLK_SSI2);
}
|
接下来是将应用层的配置参数映射到硬件寄存器。其中,qspi_dl_width决定了SPI传输模式(标准/双线/四线/八线),mode包含CPOL和CPHA配置,data_width对应数据帧大小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| if (qspi_cfg->qspi_dl_width == 1){
spi_ff = SPI_FRF_STD_SPI;
}else if (qspi_cfg->qspi_dl_width == 2){
spi_ff = SPI_FRF_DUAL_SPI;
}else if (qspi_cfg->qspi_dl_width == 4){
spi_ff = SPI_FRF_QUAD_SPI;
}else if (qspi_cfg->qspi_dl_width == 8) {
spi_ff = SPI_FRF_OCT_SPI;
}else{
return -RT_EINVAL;
}
mode = qspi_cfg_parent->mode & RT_SPI_MODE_3;
dfs = qspi_cfg_parent->data_width - 1;
qspi_reg->ssienr = 0;
qspi_reg->ser = 0;
qspi_reg->baudr = qspi_clk / max_hz;
qspi_reg->rx_sample_delay = qspi_bus->rdse << 16 | qspi_bus->rdsd;
qspi_reg->axiawlen = SSIC_AXI_BLW << 8;
qspi_reg->axiarlen = SSIC_AXI_BLW << 8;
qspi_reg->ctrlr0 = (dfs) | (mode << 8) | (spi_ff << 22);
|
这里涉及的寄存器包括:ssienr(使能控制)、ser(片选)、baudr(波特率)、rx_sample_delay(接收采样延迟)、axiawlen和axiarlen(AXI突发长度)、ctrlr0(主控制寄存器)。详细的寄存器定义参考K230技术参考手册。
传输
传输函数k230_spi_xfer根据传输模式分为两种模式:标准单线SPI和增强型多线SPI。函数首先通过判断qspi_data_lines来决定使用哪种传输方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| rt_ssize_t k230_spi_xfer(struct rt_spi_device *device, struct rt_spi_message *message)
{
struct k230_spi_dev *qspi_bus = (struct k230_spi_dev *)device->bus;
k230_spi_reg_t *qspi_reg = (k230_spi_reg_t *)qspi_bus->base;
struct rt_qspi_device *dev = (struct rt_qspi_device *)device;
struct rt_qspi_configuration *qspi_cfg = &dev->config;
struct rt_spi_configuration *qspi_cfg_parent = &dev->config.parent;
struct rt_qspi_message *msg = (struct rt_qspi_message *)message;
struct rt_spi_message *msg_parent = message;
if (msg->qspi_data_lines > 1)
{
}else {
}
}
|
增强型SPI传输
增强型SPI传输需要更复杂的参数校验和配置。代码首先验证传输参数的合法性,包括数据线数不能超过硬件配置的最大值,数据宽度必须与线数匹配等等。
传输类型trans_type用于配置spi_ctrlr0寄存器的低2位,决定指令和地址阶段的传输模式。当指令使用多线传输时设置为2,当地址使用多线传输时设置为1。如果指令和地址都使用多线,则保持trans_type为2。
1
2
3
4
5
6
7
8
9
10
11
| if (msg->instruction.qspi_lines != 1){
trans_type = 2;
}
if (msg->address.size){
if (msg->address.qspi_lines != 1){
trans_type = trans_type ? trans_type : 1;
}else if (trans_type != 0){
LOG_E("instruction or address line is invalid");
return 0;
}
}
|
增强型SPI一般涉及到大量数据的收发,驱动采用了DMA传输模式。这里的DMA是SPI控制器内部的Internal
DMA,并不是SoC的PDMA控制器,两者在硬件上完全独立,因此SPI的DMA只需要配置本控制器的寄存器,不用申请PDMA通道。
由于这个DMA直接访问物理内存,DMA传输需要使用cache对齐的缓冲区。对于发送操作,驱动将用户数据复制到对齐缓冲区并执行cache清理操作,确保数据写入内存;对于接收操作,传输完成后需要使cache无效,然后将数据复制回用户缓冲区。这种设计避免了cache一致性问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| rt_uint8_t tmod = msg_parent->recv_buf ? SPI_TMOD_RO : SPI_TMOD_TO;
rt_size_t length = msg_parent->length;
rt_size_t txfthr = length > (SSIC_TX_ABW / 2) ? (SSIC_TX_ABW / 2) : length - 1;
rt_uint8_t cell_size = (qspi_cfg_parent->data_width + 7) >> 3;
rt_uint8_t *buf = RT_NULL;
if (length){
buf = rt_malloc_align(CACHE_ALIGN_TOP(length * cell_size), L1_CACHE_BYTES);
if (buf == RT_NULL){
LOG_E("alloc mem error");
return 0;
}
}
|
寄存器配置包括传输参数和DMA设置。spi_ctrlr0的低2位是传输类型,第5-2位是地址长度(向下对齐到4字节边界),第10-8位为0x2只读,第15-11位是等待周期。FIFO阈值根据传输长度动态调整,发送阈值设置为传输长度和FIFO深度一半的较小值,接收阈值设置为FIFO深度减1,之后取消SSI_DONE和SSI_AXIE中断的掩码,最后使能DMA。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
qspi_reg->spi_ctrlr0 = trans_type | (msg->address.size & ~0x03)
| (0x2 << 8) | (msg->dummy_cycles << 11);
qspi_reg->ctrlr0 &= ~((3 << 22) | (3 << 10));
if (length)
{
qspi_reg->ctrlr0 |= (tmod << 10);
qspi_reg->txftlr = (txfthr << 16) | (SSIC_TX_ABW / 2);
qspi_reg->rxftlr = (SSIC_RX_ABW - 1);
qspi_reg->imr = (1 << 11) | (1 << 8);
qspi_reg->dmacr = (1 << 6) | (3 << 3) | (1 << 2);
qspi_reg->ctrlr1 = length - 1;
qspi_reg->spidr = msg->instruction.content;
qspi_reg->spiar = msg->address.content;
if (tmod == SPI_TMOD_TO){
rt_memcpy(buf, msg_parent->send_buf, length * cell_size);
rt_hw_cpu_dcache_clean(buf, CACHE_ALIGN_TOP(length * cell_size));
}
qspi_reg->axiar0 = (rt_uint32_t)((uint64_t)buf);
qspi_reg->axiar1 = (rt_uint32_t)((uint64_t)buf >> 32);
}
|
对于只发送指令和地址而没有数据阶段的传输,驱动禁用DMA和中断,直接通过写数据寄存器发送指令和地址,然后轮询状态寄存器等待传输完成。这种方式避免了为短传输分配DMA缓冲区和处理中断的开销:
1
2
3
4
5
6
7
8
| else{
tmod = SPI_TMOD_TO;
qspi_reg->ctrlr0 |= (tmod << 10);
qspi_reg->txftlr = ((SSIC_TX_ABW - 1) << 16) | (SSIC_TX_ABW - 1);
qspi_reg->rxftlr = (SSIC_RX_ABW - 1);
qspi_reg->imr = 0;
qspi_reg->dmacr = 0;
}
|
传输执行时先复位事件,然后使能片选和控制器。有数据传输时等待中断事件;无数据传输时直接写FIFO并轮询等待。传输完成后释放片选并禁用控制器,检查超时和DMA错误,最后处理接收数据并释放缓冲区:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| rt_event_control(&qspi_bus->event, RT_IPC_CMD_RESET, 0);
qspi_reg->ser = 1;
qspi_reg->ssienr = 1;
rt_uint32_t event;
rt_err_t err;
if (length){
err = rt_event_recv(&qspi_bus->event, BIT(SSI_DONE) | BIT(SSI_AXIE),
RT_EVENT_FLAG_OR | RT_EVENT_FLAG_CLEAR, 1000, &event);
}else
{
err = RT_EOK;
event = 0;
qspi_reg->dr[0] = msg->instruction.content;
length++;
if (msg->address.size){
qspi_reg->dr[0] = msg->address.content;
length++;
}
qspi_reg->txftlr = 0;
while ((qspi_reg->sr & 0x5) != 0x4)
{
}
}
qspi_reg->ser = 0;
qspi_reg->ssienr = 0;
if (err == -RT_ETIMEOUT){
LOG_E("qspi%d transfer data timeout", qspi_bus->idx);
if (buf){
rt_free_align(buf);
}
return 0;
}
if (event & BIT(SSI_AXIE)){
LOG_E("qspi%d dma error", qspi_bus->idx);
if (buf){
rt_free_align(buf);
}
return 0;
}
if (tmod == SPI_TMOD_RO){
rt_hw_cpu_dcache_invalidate(buf, CACHE_ALIGN_TOP(length * cell_size));
rt_memcpy(msg_parent->recv_buf, buf, length * cell_size);
}
if (buf){
rt_free_align(buf);
}
return length;
|
标准SPI传输
标准SPI传输使用中断方式而非DMA。驱动首先根据缓冲区是否空确定传输模式:只有发送缓冲区时为只发送模式(SPI_TMOD_TO),只有接收缓冲区时为只读模式(SPI_TMOD_RO),两者都有时为全双工模式(SPI_TMOD_TR)。对于只读模式,如果配置了地址,则切换为EEPROM读模式(SPI_TMOD_EPROMREAD):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| if (msg_parent->length == 0){
return 0;
}
rt_uint8_t cell_size = (qspi_cfg_parent->data_width + 7) >> 3;
rt_size_t length = msg_parent->length;
rt_size_t count = length > 0x10000 ? 0x10000 : length;
rt_size_t send_single = 0, send_length = 0, recv_single = 0, recv_length = 0;
void *send_buf = (void *)msg_parent->send_buf;
void *recv_buf = msg_parent->recv_buf;
rt_uint8_t tmod = send_buf ? SPI_TMOD_TO : SPI_TMOD_EPROMREAD;
tmod = recv_buf ? tmod & SPI_TMOD_RO : tmod;
if (tmod == SPI_TMOD_RO && qspi_cfg_parent->data_width == 8){
if ((msg->address.size & 7) || (msg->dummy_cycles & 7)){
return 0;
}
else if (msg->address.size){
if (length > 0x10000){
return 0;
}
tmod = SPI_TMOD_EPROMREAD;
}
}
|
缓冲区准备时,驱动为发送和接收分别分配临时缓冲区。对于EEPROM读模式,需要构造包含指令、地址和dummy字节的发送序列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| if (send_buf){
send_single = count;
send_buf = rt_malloc(count * cell_size);
if (send_buf == RT_NULL){
LOG_E("alloc mem error");
return 0;
}
rt_memcpy(send_buf, msg_parent->send_buf, count * cell_size);
}
else if (tmod == SPI_TMOD_EPROMREAD){
send_single = 1 + msg->address.size / 8 + msg->dummy_cycles / 8;
send_buf = rt_malloc(send_single);
if (send_buf == RT_NULL)
{
LOG_E("alloc mem error");
return 0;
}
rt_uint8_t *temp = send_buf;
*temp++ = msg->instruction.content;
for (int i = msg->address.size / 8; i; i--){
*temp++ = msg->address.content >> ((i - 1) * 8);
}
for (int i = msg->dummy_cycles / 8; i; i--){
*temp++ = 0xFF;
}
}
|
在缓冲区准备完成后,驱动需要配置寄存器并启动传输。首先将缓冲区信息保存到设备结构体中,供中断处理函数使用:
1
2
3
4
5
| qspi_bus->cell_size = cell_size;
qspi_bus->send_buf = send_buf;
qspi_bus->recv_buf = recv_buf;
qspi_bus->send_length = send_single;
qspi_bus->recv_length = recv_single;
|
接下来配置传输相关寄存器。ctrlr0设置传输模式,ctrlr1设置本次传输的数据长度。FIFO阈值配置和增强型SPI类似:发送阈值设为FIFO深度的一半,接收阈值根据传输长度动态调整。禁用DMA,使能发送空和接收满中断,配置完成后,复位事件清除之前的事件状态,然后拉低片选并使能控制器启动传输。对于只读模式,需要向数据寄存器写入一个dummy值来触发读操作
1
2
3
4
5
6
7
8
9
10
11
12
13
| qspi_reg->ctrlr0 &= ~((3 << 22) | (3 << 10));
qspi_reg->ctrlr0 |= (tmod << 10);
qspi_reg->ctrlr1 = count - 1;
qspi_reg->txftlr = ((SSIC_TX_ABW / 2) << 16) | (SSIC_TX_ABW / 2);
qspi_reg->rxftlr = count >= (SSIC_RX_ABW / 2) ? (SSIC_RX_ABW / 2 - 1) : count - 1;
qspi_reg->dmacr = 0;
qspi_reg->imr = (1 << 4) | (1 << 0);
rt_event_control(&qspi_bus->event, RT_IPC_CMD_RESET, 0);
qspi_reg->ser = 1;
qspi_reg->ssienr = 1;
if (tmod == SPI_TMOD_RO)
qspi_reg->dr[0] = 0;
|
传输线程在配置完寄存器并启动传输后,进入事件循环通过rt_event_recv阻塞等待中断事件。这个函数会挂起当前线程,直到接收到指定的事件或超时。
1
2
3
4
5
6
7
8
9
| while (RT_TRUE){
rt_uint32_t event;
rt_err_t err = rt_event_recv(&qspi_bus->event,
BIT(SSI_TXE) | BIT(SSI_RXF),
RT_EVENT_FLAG_OR | RT_EVENT_FLAG_CLEAR,
10000, &event);
}
|
当收到SSI_TXE事件时,表示当前批次的数据已经全部写入FIFO。如果还有剩余数据需要发送,驱动将下一批数据(最多64KB)复制到临时缓冲区,更新设备结构体中的缓冲区指针和长度,然后重新使能SSI_TXE中断。对于只发送模式,当所有数据都已发送后,需要轮询状态寄存器等待SPI控制器完成物理传输,因为最后一批数据可能还在FIFO中等待发送:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
if (event & BIT(SSI_TXE)){
send_length += send_single;
if (send_length < length && tmod <= SPI_TMOD_TO){
count = length - send_length;
count = count > 0x10000 ? 0x10000 : count;
rt_memcpy(send_buf, msg_parent->send_buf + send_length * cell_size, count * cell_size);
qspi_bus->send_buf = send_buf;
qspi_bus->send_length = count;
send_single = count;
qspi_reg->txftlr = ((SSIC_TX_ABW / 2) << 16) | (SSIC_TX_ABW / 2);
if (tmod == SPI_TMOD_TO)
qspi_reg->imr |= (1 << 0);
}
else if (tmod == SPI_TMOD_TO)
{
while ((qspi_reg->sr & 0x5) != 0x4)
{
}
break;
}
}
|
当收到SSI_RXF事件时,表示临时缓冲区已经接收满。驱动将数据复制到用户缓冲区,更新已接收的数据量。如果还有剩余数据需要接收,准备接收下一批数据。对于只读模式,每次只能配置一次接收长度(通过ctrlr1寄存器),因此需要禁用控制器、更新ctrlr1、重新使能控制器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
if (event & BIT(SSI_RXF)){
rt_memcpy(msg_parent->recv_buf + recv_length * cell_size, recv_buf, recv_single * cell_size);
recv_length += recv_single;
if (recv_length >= length)
{
break;
}
count = length - recv_length;
count = count > 0x10000 ? 0x10000 : count;
qspi_bus->recv_buf = recv_buf;
qspi_bus->recv_length = count;
recv_single = count;
qspi_reg->rxftlr = count >= (SSIC_RX_ABW / 2) ? (SSIC_RX_ABW / 2 - 1) : count - 1;
if (tmod == SPI_TMOD_TR){
qspi_reg->imr |= (1 << 0) | (1 << 4);
}
else if (tmod == SPI_TMOD_RO){
qspi_reg->imr |= (1 << 4);
qspi_reg->ssienr = 0;
qspi_reg->ctrlr1 = count - 1;
qspi_reg->ssienr = 1;
qspi_reg->dr[0] = 0;
qspi_reg->dr[0] = 0;
}
}
|
中断回调函数
中断回调函数是标准SPI传输的核心,负责实际的FIFO读写操作。函数通过中断向量号识别中断类型,然后执行相应的处理逻辑。
K230的每个SPI控制器有4个中断源,它们的中断向量号是连续的。通过计算向量号相对于IRQN_SPI0基址的偏移,可以确定是哪个控制器的哪种中断:
1
2
3
4
5
6
7
8
9
10
11
| static void k230_spi_irq(int vector, void *param)
{
struct k230_spi_dev *qspi_bus = param;
k230_spi_reg_t *qspi_reg = (k230_spi_reg_t *)qspi_bus->base;
vector -= IRQN_SPI0;
vector %= (IRQN_SPI1 - IRQN_SPI0);
}
|
当发送FIFO中的数据量低于阈值时触发SSI_TXE中断。中断处理函数检查状态寄存器sr的bit1(Tx
FIFO
FULL),循环将数据写入FIFO直到缓冲区为空或FIFO满。根据cell_size(数据帧大小)选择8位、16位或32位写入方式。
当缓冲区数据全部写入FIFO后,处理逻辑根据传输模式有所不同。对于只发送模式(SPI_TMOD_TO),数据全部写入FIFO并不意味着传输完成,因为FIFO中的数据可能还在等待发送。驱动将发送阈值设为0,这样当FIFO完全清空时会再次触发TXE中断,此时才发送事件通知传输线程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
if (vector == SSI_TXE){
if (qspi_bus->send_buf == RT_NULL){
qspi_reg->imr &= ~1;
}else if (qspi_bus->cell_size == 1){
while ((qspi_bus->send_length) && (qspi_reg->sr & 2)){
qspi_reg->dr[0] = *((rt_uint8_t *)qspi_bus->send_buf);
qspi_bus->send_buf++;
qspi_bus->send_length--;
}
}
if (qspi_bus->send_length == 0){
if (((qspi_reg->ctrlr0 >> 10) & SPI_TMOD_EPROMREAD) == SPI_TMOD_TO){
if (qspi_reg->txftlr)
return;
}
qspi_reg->txftlr = 0;
qspi_reg->imr &= ~1;
rt_event_send(&qspi_bus->event, BIT(SSI_TXE));
}
}
|
当接收FIFO中的数据量达到阈值时触发SSI_RXF中断。中断处理函数检查状态寄存器sr的bit3(Receive
FIFO
EMPTY),循环从FIFO读取数据直到缓冲区满或FIFO空。同样根据cell_size选择读取方式。
当剩余数据量小于当前FIFO阈值时,动态调整阈值避免最后一批数据无法触发中断。例如,如果阈值设为31(FIFO深度的一半),但只剩20个数据要接收,FIFO永远不会达到31的阈值,导致接收卡死。将阈值调整为19(剩余数据-1)可以确保最后一批数据正确接收:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| else if (vector == SSI_RXF){
if (qspi_bus->recv_buf == RT_NULL){
qspi_reg->imr &= ~0x10;
}else if (qspi_bus->cell_size == 1){
while ((qspi_bus->recv_length) && (qspi_reg->sr & 8)){
*((rt_uint8_t *)qspi_bus->recv_buf) = qspi_reg->dr[0];
qspi_bus->recv_buf++;
qspi_bus->recv_length--;
}
}
if (qspi_bus->recv_length == 0){
qspi_reg->imr &= ~0x10;
rt_event_send(&qspi_bus->event, BIT(SSI_RXF));
}
else if (qspi_bus->recv_length <= qspi_reg->rxftlr){
qspi_reg->rxftlr = qspi_bus->recv_length - 1;
}
}
|
传输完成中断(DONE)和AXI错误中断(AXIE)主要用于增强型SPI的DMA传输模式。中断处理函数只需读取相应的清除寄存器来清除中断标志,然后发送事件通知传输线程:
1
2
3
4
5
6
7
8
| else if (vector == SSI_DONE){
(void)qspi_reg->donecr;
rt_event_send(&qspi_bus->event, BIT(SSI_DONE));
}
else if (vector == SSI_AXIE){
(void)qspi_reg->axiecr;
rt_event_send(&qspi_bus->event, BIT(SSI_AXIE));
}
|
中断触发时会屏蔽调度器,导致操作系统无法进行正常的任务调度。因此驱动设计时,中断处理函数应该尽量轻量,只做必要的FIFO读写等操作,通过事件通知机制触发传输线程处理耗时操作。