硬件平台
K230架构图如下:
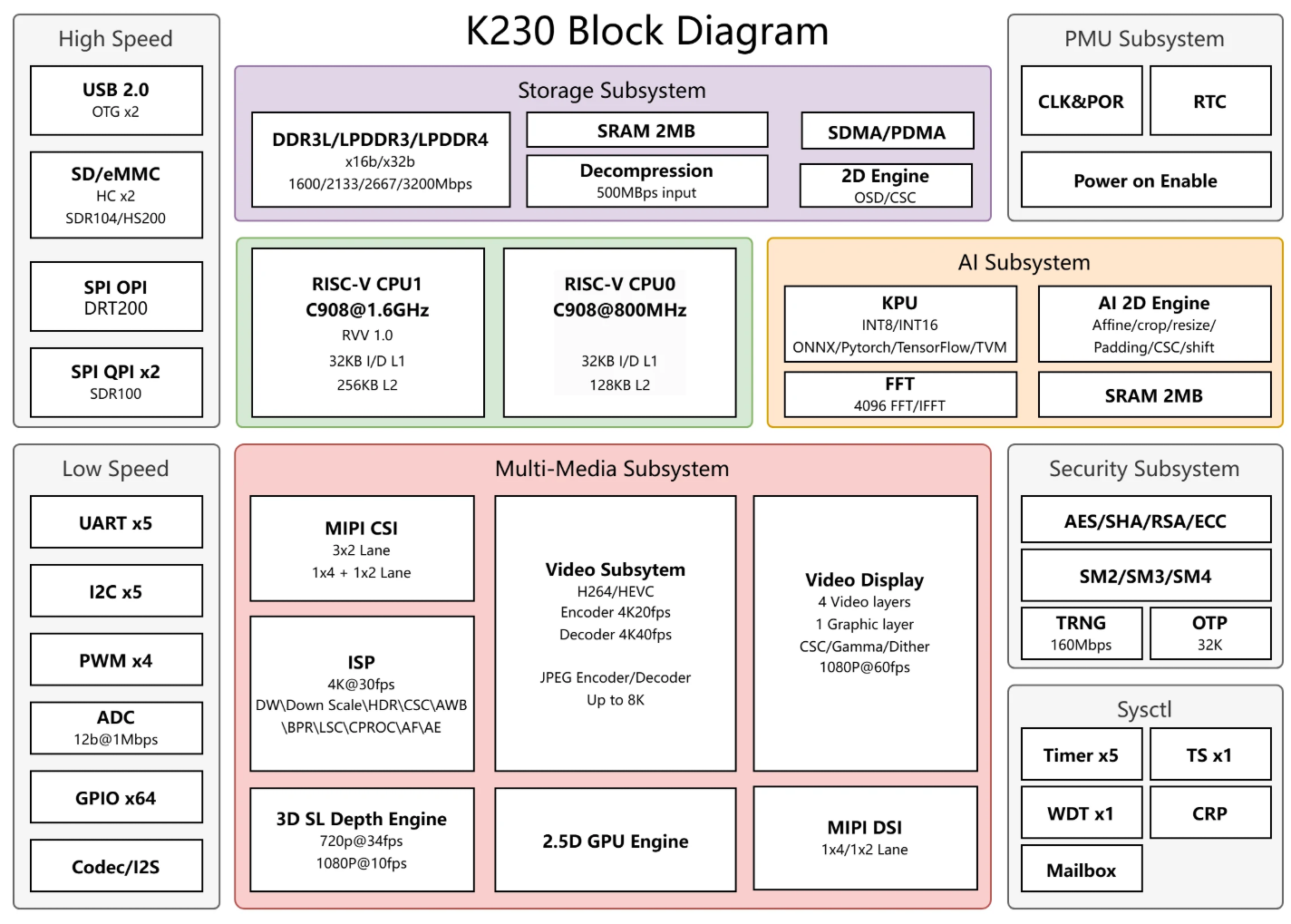 K230架构
K230架构
黄框是AI
Subsystem,里面包含了KPU、AI2D、FFT以及SRAM,这里我们只考虑KPU和AI2D。
GNNE
GNNE,或者叫KPU,这两个在嘉楠手册的Memory
Map中是同一个地址,也就是是同一个外设。
KPU用于实现神经网络算子,K230的KPU目前支持:int8和int16的卷积、池化,LSTM,RELU等算子以及一些矩阵运算。但是Solfmax等算子还是得交给CPU进行计算。具体支持算子详见:K230技术参考手册4.2
Function Description部分。
AI2D
AI2D模块主要进行图像处理,可以对来自CPU或者KPU的数据进行缩放、仿射变化、裁剪、填充等。
驱动架构设计
查阅K230技术参考手册,会发现一个问题,嘉楠并没有提供KPU的寄存器手册,和工程师沟通后,了解到GNNE的驱动分为两部分,一部分包含锁以及轮询等待,另一部分由NNCASE实现,直接在用户态进行IO内存映射。因此,想完成在K230上运行yolo之类的神经网络模型,需要三部分:NNCASE、MMZ驱动、GNNE(KPU+AI2D)驱动。
NNCASE
NNCASE是嘉楠开发的神经网络编译器,支持CPU和KPU,AI2D作为一个子模块包含在里面的。nncase大致分为两部分,一个是编译器compiler和runtime。
由于笔者在驱动移植过程中主要负责bsp部分,nncase并没有深入研究,使用方法详见:K230
nncase开发指南,嘉楠镜像中也有设计好的的demo:AI
应用开发,在menuconfig中K230 SDK Project Configuration ->RT-Smart Configuration -> Enable build Rtsmart examples中勾选即可:
 嘉楠镜像使能ai demo
嘉楠镜像使能ai demo
烧录后进入系统,cd app/examples进入工程目录执行对应历程的脚本或者elf即可。
MMZ驱动
驱动写好后,直接运行demo会报一个很奇怪的错误:
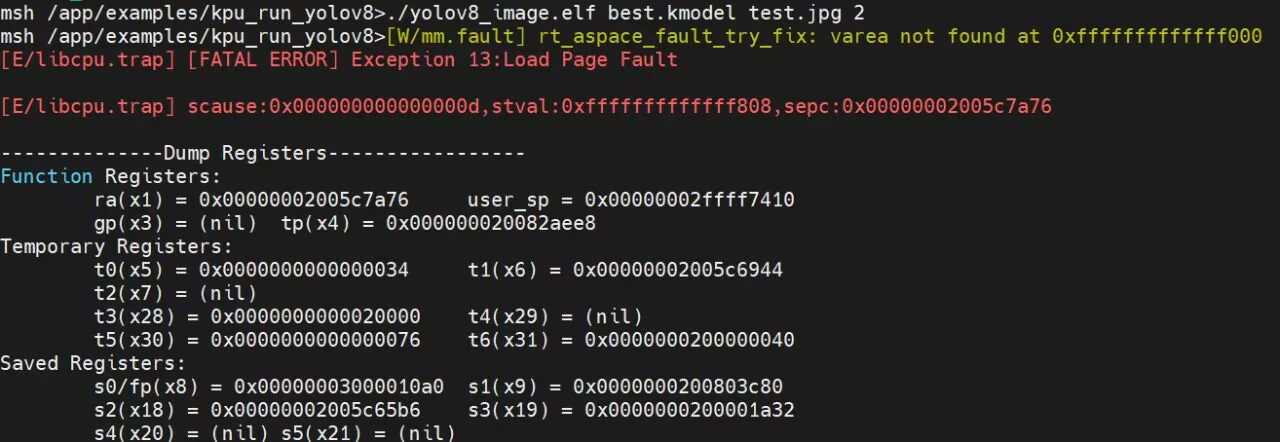 image-20251226174641753
image-20251226174641753
大致原因似乎是gp指针为0,然后有一个gp-0x800的寻址,导致指向了0xfffffffffffff800这个内核空间,并不是驱动报错。
和嘉楠工程师沟通后,发现缺少一个mmz驱动,具体在这里:mpp驱动,mmz是整个驱动下面的一个子模块。mmz驱动并没开源,嘉楠提供的是一个静态库,简单看了一下mmz的使用demo:
驱动的作用是分配非缓存内存以及带缓存的内存,以及物理/虚拟地址映射。大致猜测了一下nncase为什么会对mmz有依赖:
- 硬件加速器(GNNE、AI2D)需要物理地址进行 DMA 传输
- 需要大块连续物理内存
- 用户空间和硬件之间零拷贝共享数据
- NNCASE需要在用户态进行io内存映射
GNNE(KPU)驱动
之前提到,具体的算子实现以及内存分配由NNCASE和MMZ实现了,在GNNE驱动中,只需要实现阻塞和锁以及中断就行了。所以,对于GNNE和AI2D驱动的ops,需要有如下功能:open、close、poll、control,仔细看rtt设备子系统的结构体rt_device_ops:
1
2
3
4
5
6
7
8
9
10
| struct rt_device_ops
{
rt_err_t (*init) (rt_device_t dev);
rt_err_t (*open) (rt_device_t dev, rt_uint16_t oflag);
rt_err_t (*close) (rt_device_t dev);
rt_ssize_t (*read) (rt_device_t dev, rt_off_t pos, void *buffer, rt_size_t size);
rt_ssize_t (*write) (rt_device_t dev, rt_off_t pos, const void *buffer, rt_size_t size);
rt_err_t (*control)(rt_device_t dev, int cmd, void *args);
};
|
有open,close,control,但是没有poll,所以把GNNE当作一个设备子系统注册,dfs_file_ops恰好能满足这一点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| struct dfs_file_ops
{
int (*open)(struct dfs_file *file);
int (*close)(struct dfs_file *file);
int (*ioctl)(struct dfs_file *file, int cmd, void *arg);
ssize_t (*read)(struct dfs_file *file, void *buf, size_t count, off_t *pos);
ssize_t (*write)(struct dfs_file *file, const void *buf, size_t count, off_t *pos);
int (*flush)(struct dfs_file *file);
off_t (*lseek)(struct dfs_file *file, off_t offset, int wherece);
int (*truncate)(struct dfs_file *file, off_t offset);
int (*getdents)(struct dfs_file *file, struct dirent *dirp, uint32_t count);
int (*poll)(struct dfs_file *file, struct rt_pollreq *req);
int (*mmap)(struct dfs_file *file, struct lwp_avl_struct *mmap);
int (*lock)(struct dfs_file *file, struct file_lock *flock);
int (*flock)(struct dfs_file *file, int, struct file_lock *flock);
};
|
dfs文件系统的ops提供了ioctl可以实现硬件层面的锁,poll可以实现阻塞等待,因此,GNNE被当作一个文件注册驱动。
实现细节
GNNE和AI2D的驱动基本完全相同,虽然K230手册中提供了AI2D模块的寄存器,但是事实上AI2D的内存映射还是在NNCASE中完成的,驱动只是提供阻塞和锁等等。由于AI2D的实现和GNNE基本完全一致,这里不再讨论。
GNNE驱动实现
首先需要在驱动里实现dfs_files_ops这个结构体:
1
2
3
4
5
6
7
| static const struct dfs_file_ops gnne_input_fops =
{
.open = gnne_device_open,
.close = gnne_device_close,
.ioctl = gnne_device_ioctl,
.poll = gnne_device_poll,
};
|
gnne_device_open函数用于为每个线程创建独立的句柄,获取设备对象并保存队列等待指针,初始化锁状态为未锁定,初始化锁,最后将句柄绑定到文件描述符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| static int gnne_device_open(struct dfs_file *file)
{
struct gnne_dev_handle *handle;
rt_device_t device;
handle = rt_malloc(sizeof(struct gnne_dev_handle));
if (handle == RT_NULL)
{
gnne_err("malloc failed\n");
return -1;
}
device = (rt_device_t)file->vnode->data;
handle->wait = &device->wait_queue;
handle->is_lock = RT_FALSE;
file->data = (void *)handle;
return RT_EOK;
}
|
gnne_dev_handle结构体有两个成员,is_lock是锁,而wait是阻塞等待队列。
1
2
3
4
5
| struct gnne_dev_handle
{
rt_wqueue_t *wait;
rt_bool_t is_lock;
};
|
gnne_device_close函数用于设备的关闭,在用户空间调用
close(fd) 时被触发,负责清理资源并释放硬件锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| static int gnne_device_close(struct dfs_file *file)
{
struct gnne_dev_handle *handle;
handle = (struct gnne_dev_handle *)file->data;
if (handle == RT_NULL)
{
gnne_err("try to close a invalid handle");
return -RT_EINVAL;
}
if (handle->is_lock)
{
kd_hardlock_unlock(g_kpu_lock);
}
rt_free(handle);
file->data = RT_NULL;
return RT_EOK;
}
|
锁的实现在gnne_device_ioctl中,用户空间通过对ioctl()
的调用,实现 GNNE
硬件的访问控制。GNNE驱动的锁控制有三种模式:GNNE_CMD_LOCK用于实现自旋锁,GNNE_CMD_UNLOCK实现对硬件的解锁,而GNNE_CMD_TRYLOCK只尝试尝试一次上锁,并不进行自旋,所有的锁实现后,把值赋给每个线程字节的锁gnne_dev_handle->is_lock。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| static int gnne_device_ioctl(struct dfs_file *file, int cmd, void *args)
{
struct gnne_dev_handle *handle;
int ret = -1;
handle = (struct gnne_dev_handle *)file->data;
if ((g_kpu_lock == HARDLOCK_MAX)){
return ret;
}
if (cmd == GNNE_CMD_LOCK){
if (handle->is_lock == RT_TRUE){
return 0;
}
while(kd_hardlock_lock(g_kpu_lock));
handle->is_lock = RT_TRUE;
ret = 0;
}else if (cmd == GNNE_CMD_UNLOCK){
if (handle->is_lock == RT_FALSE){
return 0;
}
kd_hardlock_unlock(g_kpu_lock);
handle->is_lock = RT_FALSE;
ret = 0;
}else if (cmd == GNNE_CMD_TRYLOCK){
if (handle->is_lock == RT_TRUE){
return 0;
}
if (!kd_hardlock_lock(g_kpu_lock)){
handle->is_lock = RT_TRUE;
ret = 0;
}
}
return ret;
}
|
如果学过操作系统关于竞争与冒险这一部分,应该知道,上锁的语句必须是原子性的,kd_hardlock_lock(g_kpu_lock)的实现如下(hardlock/drv_hardlock.c):
1
2
3
4
5
6
7
8
9
10
11
| int kd_hardlock_lock(hardlock_type num)
{
if(num < 0 || num >= HARDLOCK_MAX)
return -1;
if(!readl(hardlock.hw_base + num * 0x4)){
LOG_D("hardlock-%d locked\n", num);
return 0;
}
LOG_D("hardlock-%d is busy\n", num);
return -1;
}
|
核心是通过readl(hardlock.hw_base + num * 0x4)这个原子性的操作实现上锁,g_kpu_lock在hardlock/drv_hardlock.h被定义为2,hardlock.hw_base指向Mailbox基地址的0x00A0,也就是这个寄存器: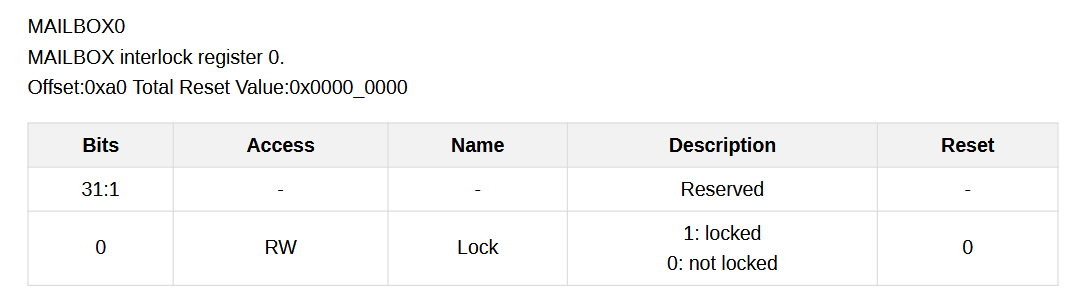
通过num*0x04进行32位寄存器的寻址,如果读到是0,则为上锁。相比于kd_hardlock_lock(hardlock_type num),kd_hardlock_unlock(hardlock_type num)多了一句写0解锁的操作。
1
2
3
4
5
6
7
8
9
10
11
| void kd_hardlock_unlock(hardlock_type num)
{
if(num < 0 || num >= HARDLOCK_MAX)
return;
if(readl(hardlock.hw_base + num * 0x4))
{
writel(0x0, hardlock.hw_base + num * 0x4);
}
LOG_D("hardlock-%d unlock\n", num);
}
|
gnne_device_poll实现了GNNE的poll接口,调用gnne_input_fops.poll后,调用rt_event_recv进入阻塞,释放CPU,等待GNNE硬件完成计算,中断唤醒这个任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int gnne_device_poll(struct dfs_file *file, struct rt_pollreq *req)
{
struct gnne_dev_handle *handle;
unsigned int flags;
handle = (struct gnne_dev_handle *)file->data;
if (!handle)
{
gnne_err("gnne_dev_handle NULL!");
return -EINVAL;
}
rt_event_recv(&g_gnne_event, 0x01, RT_EVENT_FLAG_OR | RT_EVENT_FLAG_CLEAR, RT_WAITING_FOREVER, NULL);
rt_poll_add(handle->wait, req);
return POLLIN;
}
|
唤醒的事件来自irq_callback,设备就绪的中断发出后,中断回调函数清空标志位,唤醒等待队列并发送事件,唤醒阻塞中的gnne_device_poll。其中,__iowmb()是内存屏障,确保在清除中断标志之前,所有之前的内存操作都已完成,防止编译器或
CPU 重排序导致中断标志过早清除。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static void irq_callback(int irq, void *data)
{
rt_wqueue_t *wait = (rt_wqueue_t *)data;
volatile void *write_addr = (void *)((char *)gnne_base_addr + 0x128);
if (gnne_base_addr == RT_NULL)
{
gnne_err("gnne interrupts while the hardware is not yet initialized\n");
}
__iowmb();
*(rt_uint64_t *)write_addr = 0x400000004;
rt_wqueue_wakeup(wait, (void *)POLLIN);
rt_event_send(&g_gnne_event, 0x1);
}
|
整体调用流程大致如下:
sequenceDiagram
participant User as 用户进程
participant Poll as gnne_device_poll()
participant Event as rt_event_recv()
participant HW as GNNE 硬件
participant IRQ as irq_callback()
User->>Poll: 调用 poll()
Poll->>Event: rt_event_recv() 阻塞等待
Note over Event: 等待事件 g_gnne_event
HW->>HW: 完成计算
HW->>IRQ: 触发中断
IRQ->>IRQ: 清除中断标志<br/>*(0x128) = 0x400000004
IRQ->>Event: rt_event_send(g_gnne_event)
Note over Event: 事件到达,唤醒
Event-->>Poll: 返回
Poll->>Poll: rt_poll_add() 注册等待队列
Poll-->>User: return POLLIN
Note over User: poll() 返回,数据可读
需要注意的是,这个实现与标准的 poll 机制有所不同:
- 标准 poll:先注册等待队列,如果没有数据则返回
0,有数据时通过等待队列唤醒
- 这个实现:先通过
rt_event_recv
同步等待,等待完成后才注册等待队列
这种设计可能是因为: 1.
实际的同步机制完全依赖事件机制(rt_event_recv /
rt_event_send) 2. rt_poll_add 只是为了满足
poll 框架的接口要求 3. 具体的时序要求与 NNCASE 的调用方式有关
这使得 poll
调用总是阻塞的,更像是一个”同步等待硬件完成”的接口,而不是传统的非阻塞轮询。